我們的團隊與使命
我們是 Exoplanet Hunters,一群熱情的開發者、數據科學家與太空愛好者。我們的使命是利用 AI 的力量,徹底改變我們發現遙遠世界的方式。
我們是 Exoplanet Hunters,一群熱情的開發者、數據科學家與太空愛好者。我們的使命是利用 AI 的力量,徹底改變我們發現遙遠世界的方式。


我們開發了一個基於 XGBoost 的優化機器學習模型,並將其部署在一個簡單的網頁介面後端。讓任何人都能成為系外行星獵人。
我們使用了來自 NASA 系外行星檔案庫的數據進行訓練,其中包含了:

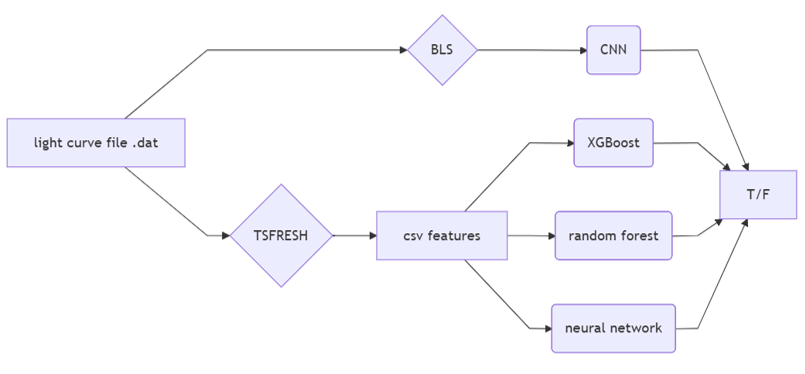


我們的工具為研究人員提供了一個快速、經統計驗證的方法來篩選行星候選者,能大幅減少手動分析時間,讓他們能更專注於最有潛力的目標上。
這個易於使用的介面,打破了科學的壁壘,能激勵公民科學家和學生直接與真實的 NASA 數據互動,點燃他們對宇宙探索的熱情。


我們的模型和特徵工程方法具有高度的可移植性。
未來能直接應用於新的時間序列數據集,確保與 TESS 和 PLATO 等未來任務數據的無縫接軌,持續為天文學界做出貢獻。
我們站在巨人的肩膀上,使用了這些強大的開源技術:

Exoplanet Hunters | Questions & Answers